
咨询电话
400-123-4567
手 机:13988999988
电 话:400-123-4567
传 真:+86-123-4567
邮 箱:[email protected]
地 址:广东省广州市天河区88号
电 话:400-123-4567
传 真:+86-123-4567
邮 箱:[email protected]
地 址:广东省广州市天河区88号

微信扫一扫
阿里巴巴释放并打开了Qianwen3,说费用只需要深度
作者:bet356亚洲版本体育日期:2025/05/01 10:33浏览:
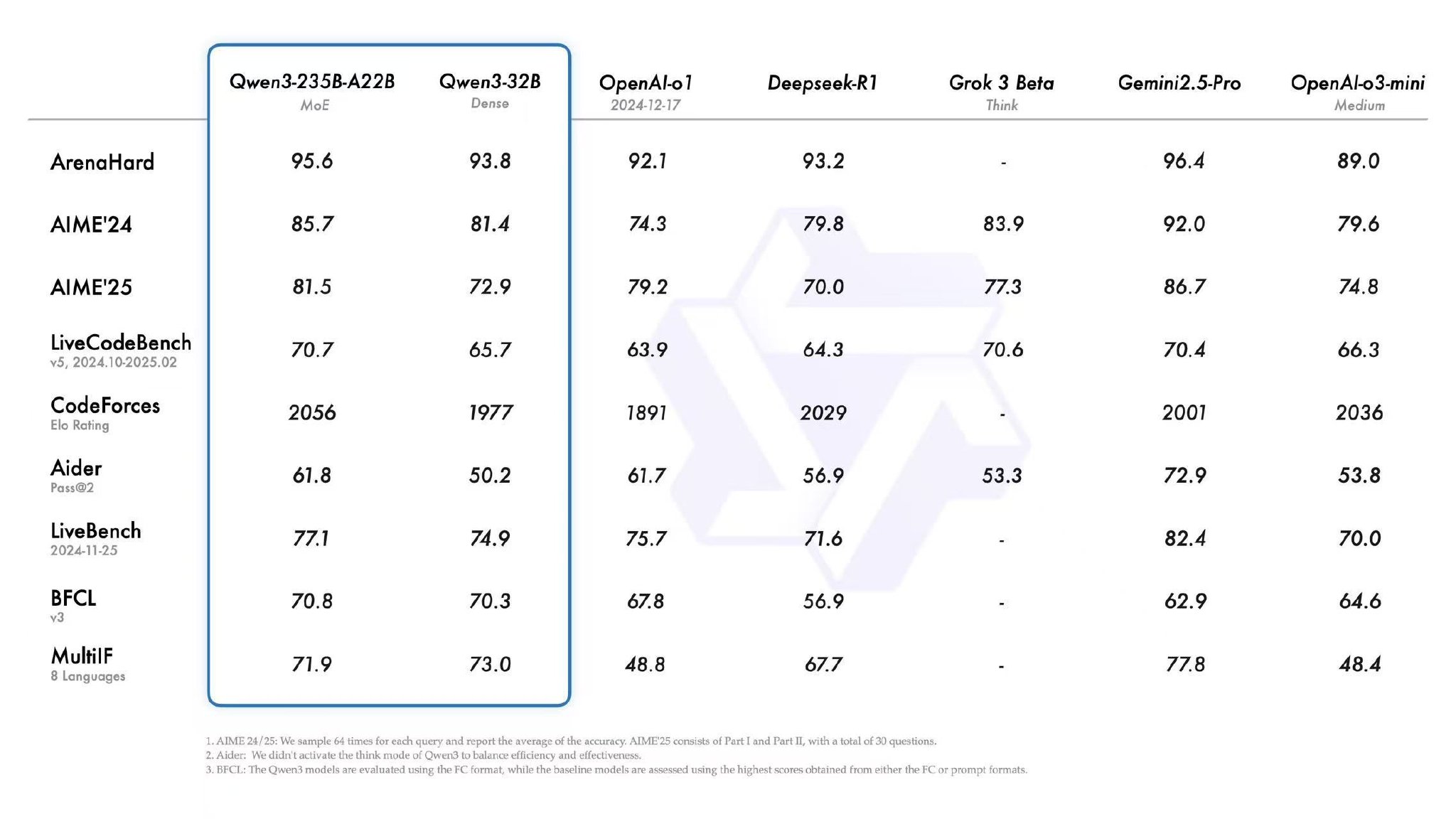 4月29日凌晨,阿里巴巴宣布推出了新一代的汤蒂·Qianwen Model Qwen3(Qianwen3),并转向采购。阿里巴巴云说,Qianwen3是中国的第一个“混合推理模型”,该模型将“快速思考”和“缓慢思考”结合到同一模型中。参数量仅为DeepSeek-R1的1/3,成本大幅下降。在诸如聊天机器人竞技场之类的列表上,该性能超出了世界领先的模型,例如R1和OpenAI-O1,并以世界上最强大的开放资源模型排名。熟悉此事的人告诉这些记者,这是今年上半年阿里巴巴云产品的主要技术发布。具体而言,汤蒂·Qianwen(Tongyi Qianwen)正式发布的技术博客表明,Qianwen3采用了混合专家(MOE)的架构,总数为235b,只有22B所需的量。培训前数据的成本达到36T,并且许多增强研究被添加到训练后阶段。同时,非思想模式被无缝集成到思维模型中。对于简单的需求,您可以“快速思考”和“返回秒”答案。对于复杂的问题,您可以在许多步骤中“深入思考”。两种模式的组合提高了该模型实现稳定有效控制“预算思维”的能力。阿里巴巴云说,尽管表现大大提高,但扩大Qianwen 3的成本已大大下降。只能使用4 H20来部署Qianwen 3全血版本,而视频记忆消耗仅为Deviceek-R1的三分之一。目前,QI打开了2 30B和235B MOE模型,以及6种密集型型号,包括0.6B,1.7B,4B,8B,8B,14B,32B。阿里巴巴云宣布,30B Qianwen3模型参数已达到了10次以上模型的改进模型使用。只有3B激活可以实现先前的生成的性能N QWEN2.5-32B型号。所有Qianwen3模型均为混合漏洞模型。 API可以设定“思维预算”(即,期望成为最大的深入思考的代币数量),灵活满足了AI应用程序的不同需求以及对性能和成本的各种情况。在开放资源之后,用户可以下载模型并在摩德族社区和拥抱面上的平台上使用它们,或者由阿里巴巴·克罗德·贝利安(Alibaba Clod Bailian)使用它们来称呼Qianwen3的API服务。单个用户可以通过Thyi应用程序体验Qianwen 3。记者发现,夸克即将连接到Qianwen 3。将来,Qianwen3将通过优化建筑模型和培训技术来改善模型,以实现一些基本目标:扩大数据量表,增加模型规模,扩展上下文长度,扩展上下文长度,扩大模态量表以及使用环境推理。 “ QWEN3代表了我们通用人工智能(AGI)和超级人工智能旅程的重要里程碑l智能(ASI)。我们相信,我们正在从一段时间内专注于培训模型,以围绕代理人的培训模型。透明
4月29日凌晨,阿里巴巴宣布推出了新一代的汤蒂·Qianwen Model Qwen3(Qianwen3),并转向采购。阿里巴巴云说,Qianwen3是中国的第一个“混合推理模型”,该模型将“快速思考”和“缓慢思考”结合到同一模型中。参数量仅为DeepSeek-R1的1/3,成本大幅下降。在诸如聊天机器人竞技场之类的列表上,该性能超出了世界领先的模型,例如R1和OpenAI-O1,并以世界上最强大的开放资源模型排名。熟悉此事的人告诉这些记者,这是今年上半年阿里巴巴云产品的主要技术发布。具体而言,汤蒂·Qianwen(Tongyi Qianwen)正式发布的技术博客表明,Qianwen3采用了混合专家(MOE)的架构,总数为235b,只有22B所需的量。培训前数据的成本达到36T,并且许多增强研究被添加到训练后阶段。同时,非思想模式被无缝集成到思维模型中。对于简单的需求,您可以“快速思考”和“返回秒”答案。对于复杂的问题,您可以在许多步骤中“深入思考”。两种模式的组合提高了该模型实现稳定有效控制“预算思维”的能力。阿里巴巴云说,尽管表现大大提高,但扩大Qianwen 3的成本已大大下降。只能使用4 H20来部署Qianwen 3全血版本,而视频记忆消耗仅为Deviceek-R1的三分之一。目前,QI打开了2 30B和235B MOE模型,以及6种密集型型号,包括0.6B,1.7B,4B,8B,8B,14B,32B。阿里巴巴云宣布,30B Qianwen3模型参数已达到了10次以上模型的改进模型使用。只有3B激活可以实现先前的生成的性能N QWEN2.5-32B型号。所有Qianwen3模型均为混合漏洞模型。 API可以设定“思维预算”(即,期望成为最大的深入思考的代币数量),灵活满足了AI应用程序的不同需求以及对性能和成本的各种情况。在开放资源之后,用户可以下载模型并在摩德族社区和拥抱面上的平台上使用它们,或者由阿里巴巴·克罗德·贝利安(Alibaba Clod Bailian)使用它们来称呼Qianwen3的API服务。单个用户可以通过Thyi应用程序体验Qianwen 3。记者发现,夸克即将连接到Qianwen 3。将来,Qianwen3将通过优化建筑模型和培训技术来改善模型,以实现一些基本目标:扩大数据量表,增加模型规模,扩展上下文长度,扩展上下文长度,扩大模态量表以及使用环境推理。 “ QWEN3代表了我们通用人工智能(AGI)和超级人工智能旅程的重要里程碑l智能(ASI)。我们相信,我们正在从一段时间内专注于培训模型,以围绕代理人的培训模型。透明相关文章
- 2025/05/01阿里巴巴释放并打开了Qianwen3,说费用只
- 2025/04/30火山引擎
- 2025/04/30没有CMF Buds 2系列TRUE无线耳机发布,最多
- 2025/04/29哪个流氓游戏最有趣?前十名的排名应该